

پیشبینی تروایی در یک مخزن متراکم گازی با استفاده از ماشین برداری پشتیبان و شبکه عصبی مصنوعی
صادق بازیار[1]؛ مجید نبی بیدهندی[2]؛ محمد مبین غفوری3؛ عبدالحسن بهرامی4
چكيده
تولید نفت و گاز از مخازن نامتعارف با چالشهای فراوانی روبرو است که در این بین تعیین دقیق ویژگیهای پتروفیزیکی میتواند امری راهگشا در توسعه مخزن باشد. درواقع بدون تعیین دقیق این ویژگیها، تحلیل دقیق بسیاری از مسائل مهندسی نفت ناممکن میباشد. تراوایی از مهمترین ویژگیهای مورد بحث در مطالعات پتروفیزیکی مخازن هیدروکربوری میباشد. این ویژگی معمولا در آزمایشگاه و از آنالیز مغزه تعیین میگردد. پیشبینی تراوایی از روی نگارهای چاه به این دلیل مهم است که آنالیز مغزه به دلیل هزینههای بسیار زیاد و زمانبر بودن فقط برای تعداد کمی از چاههای حفرشده موجود میباشد، درحالیکه داده نگارهای پتروفیزیکی برای اکثر چاهها موجود بوده و اطلاعات پیوستهای از ویژگیهای سازند در طول چاه به دست میدهند. برای پیشبینی تراوایی از روی نگارها روابط تجربی متعددی وجود دارد که قابلیت تعمیمدهی نداشته و فقط در شرایط خاصی قابل استفادهاند. پیشرفتهای اخیر در روشهای هوش مصنوعی و یادگیری ماشینی روشهای مناسبی را برای ساخت مدلهایی از تراوایی در مخازن ناهمگون فراهم نموده است. در این پژوهش، از ماشین برداری پشتیبان و شبکه عصبی مصنوعی پرسپترون چندلایه برای ساختن مدلهای پیشبینی تراوایی در یک مخزن متراکم گازی استفاده شده تا توانایی آنها در تعیین روابط بین ویژگیهای پتروفیزیکی سنجیده شود. عملکرد این روشها با یکدیگر نیز مقایسه گردید. آنالیز خطاها نشان میدهد که ماشین برداری پشتیبان قابلیت بالایی در پیشبینی تراوایی در مخازن متراکم گازی دارد و حتی میتواند عملکرد بهتری نسبت به شبکههای عصبی مصنوعی داشته باشد.
كليدواژهها: تراوایی، مخازن متراکم گازی، ماشین برداری پشتیبان، شبکه عصبی مصنوعی پرسپترون چندلایه
مقدمه
تراوایی از ویژگیهای تعیین کننده محیط متخلخل است که توانایی آن در انتقال سیال را اندازهگیری میکند. این مشخصه تحت تأثیر چند عامل است مانند مشخصههای محیط متخلخل، نوع محیط متخلخل، میزان و توزیع کانیهای رسی، ترکیب سنگ و اندازه دانهها [1]. تراوایی از مهمترین ویژگیها در مطالعات مهندسی مخزن است. تراوایی معمولا از طریق تجربی و با عبور دادن یک سیال با گرانروی مشخص درون یک مغزه با ابعاد مشخص و با اندازهگیری میزان نرخ جریان و افت فشار محاسبه میگردد.
تراوایی را با استفاده از روابط همبستگی بین تخلخل و تراوایی که از اطلاعات تحلیل مغزه به دست میآید نیز میتوان اندازهگیری نمود. اولین بار کوزنی [2] رابطهای بین تراوایی و تخلخل سنگ مطرح کرد. پس از وی، پژوهشگرانی مانند وایلی[3]، رز[4] [3]، کارمن[5] [4] و تیزیر [5] [6] روابطی را برای به دست آوردن تراوایی بر اساس مدلهای تجربی ارائه نمودند. یکی از عمدهترین نقایص مدلهای تجربی این است که آنها با استفاده از همه داده موجود ساخته شدهاند و دقت پیشبینی درون مجموعه داده آموزشی بالا است. ولی، این مدلها قابلیت تعمیمدهی کمی دارند.
این امر میتواند سبب خطاهای چشمگیری در مدل کردن تراوایی به ویژه در مخازن گاز متراکم گردد. شبکههای عصبی مصنوعی برای پیشبینی تراوایی به کار گرفته شدهاند و عملکرد بهتر و تعمیمدهی خوبی نشان دادهاند. در پژوهش هانگ[7] و همکاران [6] مقایسهای بین تراوایی تخمین زده شده از طریق شبکه عصبی، روش رگرسیون خطی چندگانه (MLR)[8] و روش رگرسیون غیرخطی چندگانه (MNLR)[9] صورت گرفت نتایج حاصل شده از روش MLR، ضعیفتر از شبکه عصبی بودند. سپس روش MNLR با استفاده از روند لونبرگ-مارکواردت[10] که یک تابع وزنی مختص داشت برای تخمین تراوایی استفاده شد. نتایج تقریبا بهتر از آنالیز MLR است ولی نسبت به شبکه عصبی نتایج ضعیفتری نشان میدهد.
مدلهای هیبرید[11] حاصل ترکیب دو یا چند مدل هوش مصنوعی میباشند. اکثر مدلهای هیبرید براساس مدل شبکه عصبی میباشند. چند مدل هیبرید برای پیشبینی تراوایی مطرح گردیده است. هلمی[12] و فتاحی[13] هیبریدی از منطق فازی، ماشین برداری پشتیبان و شبکه تابعی توسعه دادند[7]. کاریمپولی[14] (2010) شبکه عصبی ماشین کمیتهای نظارت شده را ساخت [8]. لی[15] روش یادگیری درخت تصمیمگیری را برای مدل درخت تصمیمگیری عصبی ارتقا داد [9].
با اینکه مدل هیبرید نتایج بهتری نسبت به مدل تکی دارد، چند محدودیت به دلیل محدودیتهای شبکه عصبی دارد. تعداد و اندازههای متنوع و متغیری از لایههای پنهان وجود دارد و چندین نوع تابع انتقال در هر لایه موجود میباشد و پارامترهای الگوریتم یادگیری مانند وزنهای اولیه متغیرند. همچنین یک مسئله تطابق نادرست درحین آموزش داده به طور مکرر ایجاد میشود و درنتیجه مدل معمولا تعمیمدهی مطلوبی ندارد. مرحله یادگیری شبکه عصبی بر اساس کمینهسازی کمترین متوسط مربعات خطا است که همچنین میتواند در کمینه محلی گیر کند که میتواند باعث خطاهای بزرگی در پیشبینی گردد. با معرفی ماشینهای برداری پشتیبان[16] (SVM) و عملکرد کم نظیر آن در تعمیمدهی روابط بین داده آموزشی به داده از پیش رؤیت نشده امیدواری زیادی برای تخمین قابل قبول ویژگیهای پتروفیزیکی با استفاده از این ماشین یادگیری ایجاد شده است. ال انازی و گیتس از این روش برای پیشبینی تراوایی یک مخزن ناهمگون استفاده کرده و نتایج بسیار خوبی کسب نمودند [10].
در این پژوهش عملکرد SVM با توابع کرنل متفاوت و شبکه عصبی مصنوعی پرسپترون چندلایه[17] (MLP) در پیشبینی تراوایی در یک مخزن متراکم گازی مورد بررسی قرار گرفته است. همچنین نتایج حاصل از این دو روش با استفاده از معیارهای اندازهگیری خطا با یکدیگر مقایسه گردیده است.
شبکه عصبی پرسپترون چندلایه (MLP)
شبکه عصبی پرسپترون چندلایه (MLP) یک مدل شبکه عصبی مصنوعی پس انتشار است که مجموعهای از داده ورودی را به خروجیهای مناسب تبدیل میکند. اين شبکه عصبی برمبنای یک واحد محاسباتی به نام پرسپترون ساخته میشود. یک پرسپترون برداری از ورودیها با مقادیر حقیقی را گرفته و یک ترکیب خطی از ورودی ها را محاسبه میکند. اگر حاصل از یک مقدار آستانه بیشتر بود خروجی پرسپترون برابر با 1 و در غیر اینصورت معادل 1- واحد بود. شبکههای عصبی پرسپترون، به ويژه پرسپترون چندلايه در زمره کاربردیترين شبکههای عصبی میباشند، اين شبکهها قادرند با انتخاب مناسب تعدادلايهها و سلولهای عصبی، که اغلب هم زياد نيستند، يک نگاشت غير خطی را با دقت دلخواه انجام دهند .
پرسپترون چندلایه از سه یا تعداد بیشتری لایه (یک لایه ورودی و یک لایه خروجی و یک یا تعداد بیشتری لایه پنهان) تشکیل شده است. هر نود در یک لایه از طریق مقدار وزنی مشخص به هر نود از لایه بعد متصل میشود. جز نودهای وروی، هر نود یک نرون (یا عنصر پردازشگر) با یک تابع فعالسازی غیرخطی است، که یک تابع خطی است که ورودیها را به خروجی هر نرون تبدیل میکند، سپس از طریق جبر خطی اثبات میشود که مدل با هرتعداد لایه میتواند به مدل دولایه استاندارد ورودی خروجی کاهش یابد. وجه تمایز شبکه عصبی پرسپترون چندلایه این است که هر نرون از یک تابع فعالسازی غیرخطی استفاده میکند. MLP از یک روش یادگیری نظارتشده با نام پس انتشار برای آموزش شبکه استفاده میکند. آموزش در پرسپترون با تغییر وزنهای اتصال پس از پردازش هر قسمت از داده بر اساس مقدار خطای خروجی نسبت به مقدار مورد انتظار است، صورت میگیرد. این یک نمونه از یادگیری نظارتشده است و از طریق پس انتشار صورت میگیرد که یک تعمیم از الگوریتم حداقل مربعات در پرسپترون خطی است. MLP روشی اصلاحشده از پرسپترون خطی است و میتواند دادهای را که به طور خطی جداییپذیر نیست، تمایز دهد. نمایی از یک تابع پرسپترون چندلایه در شکل 1 آورده شده است.
شکل 1. شماتیک شبکه عصبی پرسپترون چندلایه.
ماشین برداری پشتیبان
ماشینهای برداری پشتیبان ماشینهای یادگیری هستند که اصل القایی کمینهسازی ریسک ساختاری[18] (SRM) را برای به دست آوردن تعمیمدهی خوب از روی تعداد محدودی الگوی یادگیری اجرا میکنند. برای داده پراکنده با ابعاد بالا ماشینهای برداری پشتیبان تعمیمدهی بهتری نسبت به تخمین زننده های غیرخطی قدیمی دارند که اصل القایی ریسک تجربی را استفاده میکنند [11]. SRM مرز خطا را کمینه میکند تا درحین تلاش برای کمینه کردن ریسک تجربی و یک عبارت تنظیم کننده که پیچیدگی فضای فرضیه را کنترل میکند، به عملکرد بهینهای دست یابد. ماشین برداری پشتیبان، ماشین یادگیری جدیدی است که توسط واپنیک (1995) مطرح گردید و به طور موفقیت آمیزی در تشخیص الگو، رگرسیونگیری، پردازش سیگنال، و شناسایی سیستم به کار گرفته شد. ماشین برداری پشتیبان در اکثر مواقع نتایجی به خوبی ویا حتی بهتر از شبکههای عصبی تولید میکنند، درحالیکه عموما از نظر محاسباتی آسانترند و یک تابع ریاضی حقیقی تولید میکند.
ماشین برداری پشتیبان (SVM) به شکل فعلی تا حد زیادی توسط واپنیک و همکارانش (1995) در آزمایشگاههای AT&T Bell توسعه یافت. به دلیل همین پیشزمینه صنعتی، تحقیقات در حوزه SVM به سوی کاربردهایی در دنیای واقعی سوق پیدا کرد. کارهای اولیه بر روی تشخیص خصوصیت نوری (OCR)[19] متمرکز بودند. طی مدت زمان کوتاهی طبقهبندهای برداری پشتیبان توان رقابت برای انجام کارهایی نظیر OCR و تشخیص اشیاء[20] را پیدا کرد. همچنین، در زمینه رگرسیون و پیشبینی سریهای زمانی عملکرد فوقالعادهای از خود نشان داد [12].
هم اکنون، الگوریتم SVM به یک زمینه فعال تحقیقاتی تبدیل شده است و راه خود را برای شناخته شدن به عنوان یک روش یادگیری ماشینی استاندارد هموار کرده است. از اینرو تاکنون از SVM در برخی از مسائل مرتبط با صنعت نفت نیز استفاده شده است که میتوان به تخمین اشباع آب با استفاده از ماشینهای برداری پشتیبان [13]، پیشبینی تخلخل در یک مخزن ناهمگون با استفاده از ماشین برداری پشتیبان [14]، پیشبینی ضخامت ماسهسنگ از روی شکل موج در یک میدان نفتی [15]، و پیشبینی تراوایی از روی داده نگار چاه و اندازهگیریهای مغزه با استفاده از رگرسیون برداری پشتیبان [16] اشاره کرد که در ادامه به طور مختصر به بررسی این مطالعات و نتایج آنها پرداخته میشود.
در سال 2006، ژائو و همکاران برای تشخیص آن دسته از نواحی مخزن که تجمعات اقتصادی گاز دارند، از یک مدل SVM که بر روی داده لرزهای اعمال میشد برای ساخت مدل رگرسیونی از میزان اشباع آب استفاده نمودند [13]. این کار برای تمایز مناطق با اشباع گاز کم از مناطق با اشباع گاز بالا صورت گرفت. نتایج نشان داد که SVM میتواند روش خوبی برای تخمین میزان اشباع آب در مناطقی دور از محل چاه مذکور باشد.
در سال 2007 یوئه[21] و وانگ[22] [15] از ماشین برداری پشتیبان برای پیشبینی ضخامت ماسهسنگ از روی شکل موج در یک میدان نفتی استفاده کردند که یک مدل زمینشناسی برای پیشبینی پارامترهای مختلف مخزن طراحی شد و سرعت و ضخامت لایههای زمین به عنوان داده ورودی به ماشین برداری پشتیبان داده شدند. پس از آموزش ماشین برداری پشتیبان که فقط با پنج تریس موجک لرزهای صورت گرفت، سرعت نهایی پیشبینی شده و سرعتهای نظری به دست آمدند. بیشترین خطای ضخامت و سرعت پیشبینی شده از صد و یک تریس کمتر از چهار درصد بود.
در سال 2010 ال انازی[23] و همکاران [14] به پیشبینی تخلخل در یک مخزن ناهمگون با استفاده از رگرسیون برداری پشتیبان (SVR) پرداختند و نتایج آن را با نتایج به دست آمده از روشهای شبکه عصبی پرسپترون چندلایه[24]، شبکه عصبی رگرسیون عمومی[25] و شبکه عصبی RBF [26]مقایسه کردند. آنها به این نتیجه دست یافتند که SVM میتواند به عنوان یک روش دقیق برای یادگیری از روی داده تجربی تلقی شود. نتایج به دست آمده از مدلهای SVM نسبت به سایر روشها به ازای اکثر توابع کرنل دقیقتر بودند ولی در برخی موارد مدلهای پرسپترون چندلایه و شبکه عصبی رگرسیون عمومی عملکرد بهتری داشتند. آنها همچنین زمان اجرا و حافظه به کار گرفته شده توسط SVM را یکی از محدودیتهای این روش عنوان کردند.
در سال 2011 نظری[27] و همکاران [16] از رگرسیون برداری پشتیبان برای به دست آوردن تراوایی از روی داده از روی داده نگارهای چاه و اندازهگیریهای مغزه استفاده نمودند. هدف آنها به طور خاص، بررسی عملکرد SVM در مواجهه با داده پراکنده[28] بود، چرا که روشهای مرسوم مانند شبکههای عصبی مصنوعی به هنگام استفاده از داده پراکنده و تنظیم پارامترهای مربوطه نتایج مناسبی به دست نمیدهند. نتایج نشان میدهند که اگرچه تعداد داده تراوایی که از اندازهگیری مغزه به دست آمدهاند برای برونیابی[29] تابع آموزشدیده از مشخصههای آموزشی[30] به مشخصههای آزمایشی[31] محدودند، ولی در حوزه مشخصه آموزشی مطابقت خوبی را با ایجاد همبستگی بالا نشان میدهند. در واقع بیشتر حالت غیرخطی که در فضای داده وجود دارد به فضای مشخصه منتقل میشود و سپس در آنجا با استفاده از یک SVM کمینه مربعات، فرآیند آموزش به شکل بهتری انجام میشود. همچنین مشخص شد که در حضور تعداد داده کم، SVM میتواند ابزار قابل اعتمادی برای تخمین تراوایی از روی نگارهای چاه باشد.
مخزن مورد مطالعه
این پژوهش به بررسی برخی خواص پتروفیزیکی ماسهسنگهای متراکم حاوی گاز Mesavarede میپردازد که حاوی حجم عظیمی از گاز در غرب ایالت متحده آمریکا میباشد. سازند Mesavarede در حوضههای رسوبی رودخانه سبز، پیکیانسه، یونیتا، واشاکی و رودخانه باد گسترش دارد. در این پژوهش از اطلاعات به دست آمده از حوضه رسوبی واشاکی استفاده شده است.
حوضه رسوبی واشاکی در قسمت جنوب شرق حوضه رودخانه سبز واقع میباشد. این حوضه رسوبی در جنوب طاق وامسوتر قرار دارد. این حوضه وسیع در شمال طاق ساختاری سلسله کوه چروکی قرار دارد که حوضه واشاکی را از از حوضه سندواش در کلرادو جدا میکند. حوضه واشاکی عمیقترین و به لحاظ ساختاری پیچیدهترین قسمت مجموعه Mesavarede میباشد. بیشترین شیب را در این منطقه مشاهده میکنیم و چندین بخش چینخوردگی در آن وجود دارد.
حوضه واشاکی دارای توالی ضخیمی کرتاسه بالای دریایی و سنگهای ترشیاری آغازین قارهای به همراه سنگهای دریاچهای سازند رودخانه سبز ائوسن میباشد. درون حوضه همچنین محدوده وسیعی از ماسههای ساحلی به نسبت پایدار را دارا میباشد. اکثر قسمتهای داخلی حوضه واشاکی توسعه نیافته است؛ بخشی از ناحیه، ویژگیهای فرسایشی و شکلهای غیر معمول و منحصر بفردی دارد که شهر خشتی نامیده شده است. شکل 2 نمایی از حوضه واشاکی واقع در ایالت وایومینگ[32] را نشان میدهد.
شکل 2. نمایی از حوضه رسوبی واشاکی.
روش ساخت مدلها
برای پیشبینی تراوایی مراحل کار به شرح زیر میباشد:
- ایجاد داده برای آموزش و آزمایش. برای تخمین ویژگیها از داده 3 چاه استفاده گردید. از اطلاعات این چاهها در نه مجموعه داده مختلف استفاده شد که در جدول 1 قابل مشاهده است. برای پیشبینی تراوایی، ورودی مدلها، نگارهای اشعه گاما (GR)، تخلخل نوترون (NPHI)، تخلخل صوتی (DT)، چگالی (RHOB) و مقاومت سازند (ILD) و خروجی مدل، تراوایی به دست آمده از مغزه است.
جدول 1. مجموعههای داده مختلف داده برای سنجش دقت مدلها.
| مجموعه داده | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| چاههای آموزشی | 2 | 3 | 3و2 | 1 | 3 | 3و1 | 1 | 2 | 2و1 |
| چاه آزمایشی | 1 | 1 | 1 | 2 | 2 | 2 | 3 | 3 | 3 |
- آموزش دادن مدلها با داده آموزشی. نرمافزار DTREG برای ساخت مدلهای پیشبینی ویژگیها با استفاده از داده آموزشی مورد استفاده قرار گرفت. برای ماشین برداری پشتیبان، توابع RBF، سیگمویید، و خطی استفاده شد تا دقت آنها در تخمین هریک از ویژگیها سنجیده گردد.
عملکرد مدلهای ماشین برداری پشتیبان به شدت به انتخاب مناسب پارامترهای مدل و تابع کرنل بستگی دارد. جهت یافتن مقادیر بهینه پارامترها از هردو روش جستجوی شبکه و جستجوی الگو استفاده گردید. جستجوی شبکه از مقادیری از یک بازه مشخص با استفاده از گامهای هندسی استفاده میکند. از سوی دیگر، جستجوی الگو در مرکز بازه مشخص آغاز میگردد و در هر جهت برای هر پارامتر گامهای آزمایشی برمیدارد. اگر پارامترها در نقطه جدید انطباق را بهبود بخشند، مرکز جستجو به نقطه جدید منتقل میگردد و این روند تکرار میگردد. درغیر اینصورت، اندازه گام کاهش مییابد و جستجو ادامه مییابد. جستجوی الگو زمانی متوقف میگردد که اندازه گام به یک مقدار از پیش تعیین شده کاهش یابد. جستجوی شبکه از نظر محاسباتی گران است زیرا مدل باید در خیلی از نقاط برای هر پارامتر ارزیابی گردد. این روش ممکن است گاهی از نظر محاسباتی غیرممکن باشد. از سوی دیگر، جستجوی الگو به طور کلی ارزیابیهای خیلی کمتری نسبت به جستجوی شبکه نیاز دارد. با این حال، جستجوی الگو ممکن است به جای یک نقطه بهینه مطلق به یک بهینه محلی همگرا شود. بنابراین، برای ارتقای جستجو، هر دو روش جستجو در یک روش سیستماتیک باید استفاده شوند. بهینهسازی با جستجوی شبکه آغاز میگردد تا ناحیهای را نزدیک نقطه بهینه مطلق پیدا کند. متعاقبا، جستجوی الگو در اطراف بهترین نقطه یافت شده توسط جستجوی شبکه برای یافتن نقطه بهینه صورت میپذیرد.
- مقایسه دقت پیشبینی روشها. دقت پیشبینی، توانایی یک روش تقریبزنی برای پیشبینی پاسخ مطلوب است زمانیکه با دادههای آموزشی متفاوت آموزش دیده باشد. [17]. برای مقایسه دقت روشها، همانگونه که در جدول 1 نشان داده شده است، از ترکیبهای مختلفی از اطلاعات چاهها به عنوان داده آموزشی و یک چاه به عنوان داده آزمایشی استفاده شد. برای مقایسه سه تابع کرنل، هریک به طور جداگانه استفاده شدند و تفاوت بین هر مقدار پیشبینی شده با مقدار حقیقی آن توسط ضریب همبستگی[33]، r، جذر متوسط مربعات خطا[34] ، RMSE، متوسط قدرمطلق خطا[35]، AAE، و بیشترین قدر مطلق خطا[36] ، MAE تعیین گردید که در جدول 2 توضیح داده شده است.
جدول 2. میزان خطاها برای ارزیابی دقت پیش بینی.
| عبارت ریاضی مربوطه | معیارهای اندازهگیری خطا |
| ضریب همبستگی، r | |
| جذر متوسط مربعات خطا، RMSE | |
| متوسط قدرمطلق خطا ، AAE | |
| بیشترین قدر مطلق خطا، MAE |
نتایج
شکل 3 ضریب همبستگی پیشبینیهای SVM با سه تابع کرنل مختلف (تابع RBF، سیگمویید و خطی) و شبکه عصبی پرسپترون چندلایه را در پیشبینی مقدار تراوایی نشان میدهد.
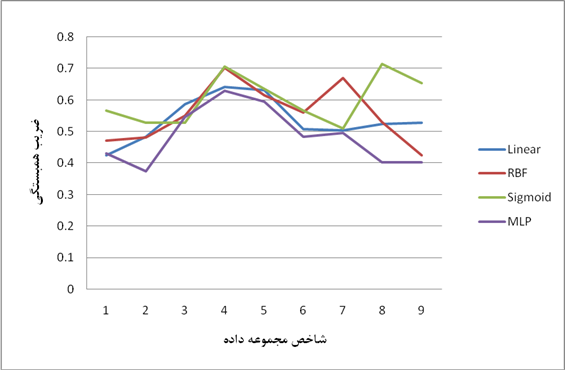
شکل 3. مقایسه عملکرد ماشین برداری پشتیبان با سه تابع کرنل مختلف (خطی، RBF، سیگمویید) و شبکه عصبی پرسپترون چندلایه در پیش بینی تراوایی.
همانگونه که در شکل 3 مشخص است، ماشینهای برداری پشتیبان عملکرد بهتری نسبت به شبکه عصبی در تخمین میزان تراوایی داشتهاند. تابع کرنل سیگمویید در 9 مجموعه داده عملکرد یکنواخت تری از خود نشان داده و خود را به عنوان بهترین مدل پیشبینی تراوایی مطرح نموده است. ضریب همبستگی ماشینهای برداری پشتیبان در پیشبینی تراوایی بین 0.4 تا 0.7 متغیر بوده و روند یکنواختی را نشان نمیدهد که این مشکل را میتوان ناشی از روابط پیچیده موجود در مخازن متراکم و مقادیر کم تراوایی دانست.
جدول 3 میزان RMSE، AAE، و MAE را برای MLP در مقایسه با SVR نشان میدهد. نتایج بیانگر این است که SVR درکل بهتر از MLP با میزان خطای کمتر عمل میکند. با این وجود استثناهایی هم وجود دارد.
همان گونه که از جدول 3 مشخص است در مجموعه داده شماره 1 کمترین میزان خطا متعلق به MLP است و این مدل شبکه عصبی از همه مدلهای ماشین برداری پشتیبان با توابع کرنل مختلف عملکرد بهتری دارد. در این مجموعه داده بهترین عملکرد در بین مدلهای SVM متعلق به مدل با تابع کرنل سیگمویید است که کمتر از دو تابع دیگر خطا دارد.
در مجموعه داده شماره 2، تابع کرنل سیگمویید عملکرد نسبی بهتری دارد و دو تابع کرنل دیگر نیز نتایج بهتری و خطاهای کمتری نسبت به MLP دارند.
جدول 2. مقدار خطاهای RMSE، AAE و MAE حاصل از پیشبینی تراوایی توسط ماشین برداری پشتیبان با توابع کرنل متفاوت(خطی، RBF و سیگمویید) و شبکه عصبی MLP.
| ماشین برداری پشتیبان | MLP | مجموعه داده | ||||||||||
| تابع خطی | تابع RBF | تابع سیگمویید | ||||||||||
| MAE | AAE | RMSE | MAE | AAE | RMSE | MAE | AAE | RMSE | MAE | AAE | RMSE | |
| 0.488 | 0.044 | 0.070 | 0.477 | 0.042 | 0.066 | 0.339 | 0.026 | 0.050 | 0.040 | 0.093 | 0.022 | 1 |
| 0.347 | 0.040 | 0.066 | 0.170 | 0.039 | 0.048 | 0.247 | 0.033 | 0.041 | 0.539 | 0.078 | 0.084 | 2 |
| 0.356 | 0.041 | 0.064 | 0.513 | 0.041 | 0.079 | 0.265 | 0.034 | 0.047 | 0.026 | 0.035 | 0.047 | 3 |
| 0.057 | 0.016 | 0.021 | 0.048 | 0.019 | 0.023 | 0.075 | 0.011 | 0.017 | 0.075 | 0.025 | 0.024 | 4 |
| 0.098 | 0.018 | 0.026 | 0.058 | 0.020 | 0.021 | 0.041 | 0.014 | 0.017 | 0.060 | 0.024 | 0.029 | 5 |
| 0.078 | 0.023 | 0.030 | 0.047 | 0.019 | 0.024 | 0.066 | 0.017 | 0.024 | 0.087 | 0.030 | 0.037 | 6 |
| 0.127 | 0.030 | 0.038 | 0.085 | 0.029 | 0.030 | 0.068 | 0.031 | 0.037 | 0.115 | 0.039 | 0.045 | 7 |
| 0.066 | 0.026 | 0.030 | 0.078 | 0.024 | 0.029 | 0.242 | 0.034 | 0.056 | 0.103 | 0.029 | 0.036 | 8 |
| 0.080 | 0.026 | 0.031 | 0.050 | 0.038 | 0.076 | 0.062 | 0.023 | 0.028 | 0.583 | 0.096 | 0.129 | 9 |
در مجموعه داده شماره 3، مدل SVM با تابع کرنل سیگمویید و شبکه عصبی MLP نتایج تقریبا مشابهی دارند و عملکردشان به هم بسیار مشابه میباشد. این دو مدل عملکرد بهتری نسبت به دو مدلهای دو تابع کرنل دیگر دارند.
در مجموعه داده شماره 4، مدل SVM با تابع کرنل سیگمویید عملکرد بسیار خوبی از خود نشان میدهد و بهترین نتایج را به دست میدهد. دو مدل دیگر SVM نیز نتایج بهتری نسبت به شبکه عصبی MLP نشان میدهند.
در مجموعه داده شماره 5، مدل SVM با تابع کرنل سیگمویید بهترین نتایج را با کمترین خطا ایجاد کرده است. دو مدل دیگر SVM نیز نتایج بهتری نسبت به شبکه عصبی MLP نشان میدهند.
در مجموعه داده شماره 6، مدلهای SVM با توابع کرنل سیگمویید RBF نتایج مشابهی داشته و بهتر از سایر مدلها عمل میکنند. مدل SVM با تابع کرنل خطی نیز عملکرد بهتری نسبت به شبکه عصبی MLP دارد.
در مجموعه داده شماره 7، مدل SVM با تابع کرنل RBF کمترین خطا را دارد. مدلهای با توابع کرنل خطی و سیگمویید عملکرد مشابهی داشته و نتایج بهتری نسبت به شبکه عصبی MLP نشان میدهند.
در مجموعه داده شماره 8، مدلهای SVM با توابع کرنل خطی و RBF عملکرد مشابهی داشته و بهترین نتایج را نشان میدهند. شبکه عصبی MLP نیز عملکرد خوبی داشته و نتایج بهتری نسبت به مدل SVM با تابع کرنل سیگمویید میدهد.
در مجموعه داده شماره 9، مدل SVM با تالع کرنل سیگمویید بهترین عملکرد را دارد. مدل SVM با تابع کرنل خطی نیز نتایج خوبی به دست میدهد. اما خطای مدلهای SVM با تابع کرنل RBF و شبکه عصبی به نسبت زیاد است.
نکته دیگری که قابل ذکر میباشد این است که نتایج همه مدلها به نسبت خوب بوده و نتایجی که پیش از این ذکر گردید برای مقایسه این مدلها بوده است. همانگونه که مشاهده شد، مدل SVM با تابع کرنل سیگمویید بهتر از سایر توابع به پیشبینی تراوایی پرداخته است. همچنین در دو مجموعه داده مشاهده گردید که شبکه عصبی MLP بهترین نتایج را ایجاد کرده است.
در شکل 4 نموداری از میزان تراوایی مغزه و تراوایی پیشبینی شده توسط مدلهای پیشبینی ارائه شده است.
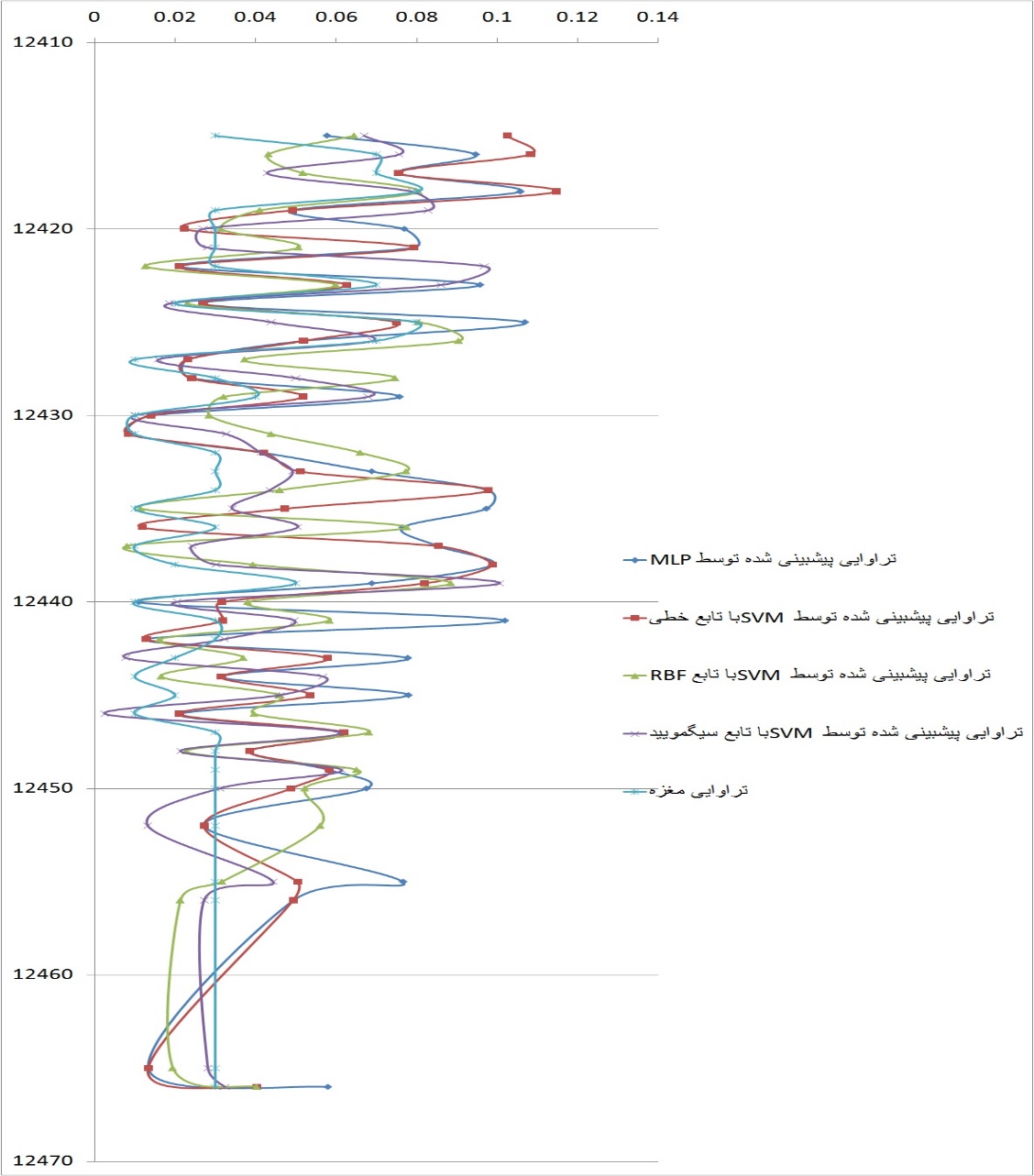
شکل 4. مقایسه تراوایی پیشبینی شده توسط مدل های مختلف و تراوایی مغزه در مجموعه داده شماره 6.
نتیجه
ماشین برداری پشتیبان و شبکه عصبی MLP برای پیشبینی تراوایی در مخزن متراکم گازی Mesavarede در حوضه رسوبی واشاکی مورد استفاده قرار گرفتند. از ماشینهای برداری پشتیبان با توابع کرنل متفاوت (خطی، RBF، سیگمویید) استفاده شده و عملکرد آنها با هم مقایسه گردید. نتیجهگیریهای حاصل از این پژوهش به شرح زیر است:
- ماشین برداری پشتیبان توانایی قابل قبولی در یادگیری از روی تعداد کم داده آموزشی داشته و پس از آموزش به خوبی میتواند به پیشبینی پارامتر هدف از روی داده از پیش رؤیت نشده بپردازد.
- ماشین برداری پشتیبان از دقت خوبی برخوردار است و نسبت به شبکه عصبی پرسپترون چندلایه عملکرد یکنواختتر و مطمئنتری در پیشبینی تراوایی از روی نگارهای پتروفیزیکی دارد که این نگارها روابط پیچیدهای با یکدیگر دارند.
- هر سه تابع کرنل خطی، RBF و سیگمویید عملکرد خوبی در پیشبینی تراوایی دارند ولی تابع کرنل سیگمویید اندکی بهتر از دو تابع کرنل دیگر عمل میکند.
- استفاده توأمان از روشهای جستجوی شبکه و جستجوی الگو میتواند بهترین ابزار جهت یافتن پارامترهای بهینه مدلهای ماشین برداری پشتیبان و توابع کرنل آنها باشد.
مراجع
[1] Donaldson, E.C. and Tiab, D.; (2004), Petrophysics: Theory and Practice of measuring reservoir rock and fluid transport properties. Gulf Professional Publishing.
[2] Kozeny, J.; (1927), Ueber kapillare leitung des wassers im boden. Sitzungsber. Akad. Wiss. Wien, 271-306. 136.
[3] Wylie, M. and Rose, W.; (1950), Some theoretical considerations related to the quantitative evaluation of electric log data. Jour. Petroleum Technology, 105-110. 189.
[4] Carman, P.; (1937), Fluid flow through granular beds. Transactions-Institution of Chemical Engineeres, 150-166. 15.
[5] Tixier, M.; (1949), Evaluation of permeability from electric-log resistivity gradients. Oil and Gas J, 113-122. 48(6).
[6] Huang, Z., et al.; (1996), Permeability prediction with artificial neural network modeling in the Venture gas field, offshore eastern Canada. Geophysics, 422-436. 61(2).
[7] Helmy, T. and Fatai, A.; (2010), Hybrid computational intelligence models for porosity and permeability prediction of petroleum reservoirs. International Journal of Computational Intelligence and Applications, 313-337. 9(04).
[8] Karimpouli, S., Fathianpour, N. and Roohi, J.; (2010), A new approach to improve neural networks’ algorithm in permeability prediction of petroleum reservoirs using supervised committee machine neural network (SCMNN). Journal of Petroleum Science and Engineering, 227-232. 73(3).
[9] Li, X. and Chan, C.; (2010), Application of an enhanced decision tree learning approach for prediction of petroleum production. Engineering Applications of Artificial Intelligence, 102-109. 23(1).
[10] Al-anazi, A.F., Gates, I.D., and Azaiez, J.; (2009), Innovative data-driven permeability prediction in a heterogeneous reservoir. in EUROPEC/EAGE Conference and Exhibition 2009. Society of Petroleum Engineers.
[11] Cherkassky, V. and Mulier, F.M.; (2007), Learning from data: concepts, theory, and methods. John Wiley & Sons.
[12] Smola, A.J. and Schölkopf, B.; (2004), A tutorial on support vector regression. Statistics and computing, 199-222. 14(3).
[13] Zhao, B., et al.; (2006), Water saturation estimation using Support Vector Machine. in SEG/New Orleans 2006 Annual Meeting. 1693-1696.
[14] Al-Anazi, A. and Gates, I.; (2010), Support vector regression for porosity prediction in a heterogeneous reservoir: A comparative study. Computers & Geosciences, 1494-1503. 36(12).
[15] Yue, Y. and Wang, J.; (2007), SVM method for predicting the thickness of sandstone. Applied Geophysics, 276-281. 4(4).
[16] Nazari, S., Kuzma, H.A. and Rector, J.W.; (2011), Predicting Permeability From Well Log Data And Core Measurements Using Support Vector Machines. in 2011 SEG Annual Meeting 2011. Society of Exploration Geophysicists.
[17] Jin, R., Chen, W. and Simpson, T.W.; (2001), Comparative studies of metamodelling techniques under multiple modelling criteria. Structural and Multidisciplinary Optimization, 2001. 23(1): p. 1-13.
 |
1st National Conference on Petroleum Geomechanics
International Convention Center of RIPI Tehran, May,12-14,2015 |
Predicting Permeability in a Tight Gas Reservoir by using Support Vector Machine and Artificial Neural Network
Sadegh Baziar[37]; Majid Nabi-Bidhendi[38]; Mohammad Mobin Ghafoori[39]; Abdolhasan Bahrami4
ABSTRACT
Oil and gas production from tight gas reservoirs, has many challenges. Determination of petrophysical properties can be a key element. In fact, it is not possible to have accurate solutions to many petroleum engineering problems without having accurate measurement of these properties. Permeability is one of the most important petrophysical properties. Permeability is often measured in laboratory from core samples. The prediction of permeability using well log data is important because the core analysis are usually only available from a few wells in a field and have high coring and laboratory analysis costs, while most wells are logged and well logs provide continuous records across the well. The common practice is to estimate properties from logs using empirical equations developed from limited core data; however, these correlation formulae are not universally applicable. Recent advances in machine learning methods have provided attractive alternatives for constructing interpretation models of rock properties in heterogeneous reservoirs. Here, support vector machines and multilayer perceptron neural network have been used to predict permeability in Mesaverde formation, located in Washakie basin. Results these two methods in predicting permeability have been compared. Error analysis revealed that support vector machines have great capabilities in predicting permeability tight reservoirs and can perform even better than neural networks.
Keywords: permeability, tight gas reservoirs, support vector machine, multilayer perceptron neural network
- نویسنده مسوول: کارشناسی ارشد مهندسی اکتشاف نفت، دانشگاه صنعتی امیرکبیر، baziar@aut.ac.ir ↑
- نویسنده دوم: استاد، مؤسسه ژئوفیزیک دانشگاه تهران، mnbhendi@ut.ac.ir ↑
- Wylie ↑
- Rose ↑
- Carman ↑
- Tixier ↑
- Haung ↑
- Multiple linear regression ↑
- Multiple non-linear regression ↑
- Levenberg-Marquardt ↑
- Hybrid models ↑
- Helmi ↑
- fatahi ↑
- Karimpouli ↑
- li ↑
- Support Vector Machine ↑
- Multilayer Perceptron ↑
- Structural Risk Minimization ↑
- Optical character recognition ↑
- Object recognition ↑
- Yue ↑
- Wang ↑
- Al-Anazi ↑
- Multilayer Peceptron Neural Network ↑
- General Regression Neural Network ↑
- Radial Basis Function Neural Network ↑
- nazari ↑
- Sparse data ↑
- Extrapolate ↑
- Learn features ↑
- Test features ↑
- Wyoming ↑
- Correlation coefficient ↑
- Root mean square error ↑
- Average absolute error ↑
- Maximum absolute error ↑
- Corresponding Author: MSc of Exploration Engineering, Amirkabir University of Technology, baziar@aut.ac.ir ↑
- Professor of Geophysics, Institute of Geophysics, University of Tehran. ↑
-
Persian Gulf Science and Technology Park, Bushehr
4Persian Gulf Science and Technology Park, Bushehr ↑